
I detta inlägg ska vi gå igenom problem med heteroskedasticitet (och inte bara hur svårt det är att stava och uttala). Heteroskedasticitet är ett av de vanligare problemen som kan uppstå i, och försvåra tolkningen av, en regressionsanalys. Heteroskedasticitet innebär i korthet att variansen hos feltermerna inte är konstant; det vill säga att, när värdet på oberoende variabel (x) ökar, så minskar eller /ökar den oförklarade variationen i beroende variabel (y). Är spridningen jämn råder motsatsen homoskedasticitet.
I en bivariat regression kan uppenbar heteroskedasticitet ganska enkelt visa sig genom en enkel scatterplot, som den nedan.
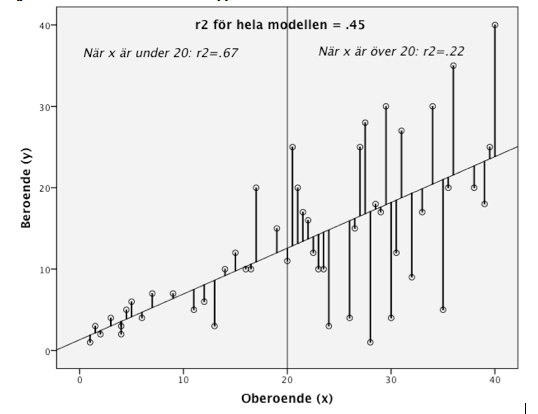
I figuren ser vi att observationerna med lägre x är mer samlade längs regressionslinjen på y-axeln, och blir större när x ökar (linjerna mellan regressionslinjen och observationerna blir allt längre). Det uppstår ett ’megafonmönster’. Heteroskedasticitet kan naturligtvis se ut på många olika sätt, t. ex. som ett ’timglas’ (när observationerna är minst när x är medelhög, och större vid större och mindre värden på x). I modeller med färre observationer kan även problem med en eller ett par outliers ställa till det.
Varför är detta ett problem?
En förutsättning för att en OLS-regression skall återge så korrekta estimat/koefficienter som möjligt är att feltermerna/residualerna i variablerna är så små som möjligt (därav namnet Ordinary LEAST Squares). Dessutom förutsätter OLS att dessa feltermer är konstanta (homoskedastiska). Om så inte är fallet kommer standardfelen för koefficienterna att se större eller mindre ut än vad de egentligen skall vara. Detta medför i sin tur att signifikanstesterna på estimaten/koefficienterna inte blir korrekta utan antingen vara för ”lätta” eller för ”svåra” att få signifikans när signifikansen beräknas.
Intuitivt kan detta förstås genom att tänka att modellen (som i figuren ovan) fungerar olika bra beroende på var längs x-axeln vi tittar. Där x är lågt och observationerna ligger nära regressionskoefficienten fungerar modellen (regressionslinjen) tämligen bra, medan modellen vid höga x-värden blir allt mindre effektiv. Som vi ser ovan har modellen betydligt större förklaringskraft (mätt i r2) när x är under 20, jämfört med när x är över 20.
Då variansen bland de värden som skiljer sig mest från regressionslinjen har större tyngd än de som passar in bättre får dessa större betydelse för att räkna ut standardfelen.
Hur hittar vi heteroskedasticitet och hur kan vi lösa det?
Ett mycket vanligt skäl till heteroskedasticitet är att man utelämnat en variabel som påverkar y (detta kallas på statistikspråk för omitted variable bias). På så vis kan detta problem ses som en möjlighet att tänka över om man missat att inkludera något viktigt i sin modell och på så vis förbättra den slutgiltiga analysen. Vi kan även testa att logaritmera variabler (som tidigare avhandlats här) för att få feltermerna att bli jämnare spridda längs regressionslinjen.
För det första är det möjligt att, som ovan, helt enkelt titta på förhållandet mellan den beroende och den oberoende variabeln och uttyda om det finns något mönster. När vi använder oss av en multivariat regression kan vi spara residualerna (feltermerna) och köra en scatterplot mot varje oberoende variabel. På så vis kan vi ofta identifiera om ett heteroskedastiskt förhållande som råder, samt huruvida det är en viss oberoende variabel som orsakar den.
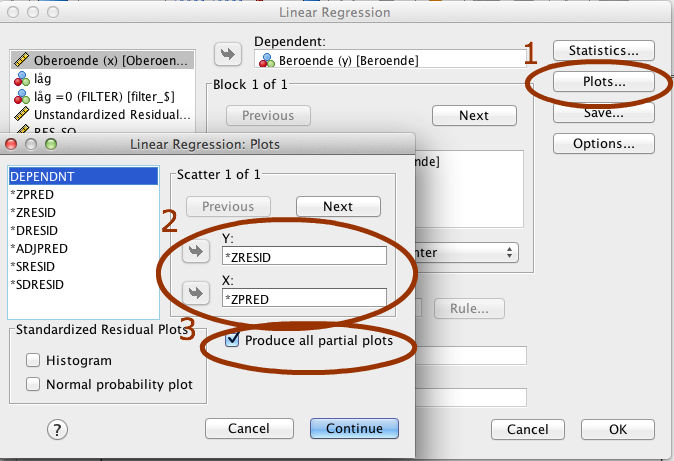
SPSS ger oss möjligheten att enkelt ta fram dessa figurer genom att klicka på ’plots’-rutan under regressionsfönstret. Dra sedan över ’ZRESID’ från vänstra fältet till rutan under Y, samt ’ZPRED’ till rutan under X. Detta skapar en plot där residualerna fördelas efter de förväntade värdena för hela regressionen. Har vi flera oberoende variabler kan det också vara bra att bocka för ’Produce all partial plots’, för att se hur residualerna fördelas utefter varje oberoende variabel för sig.
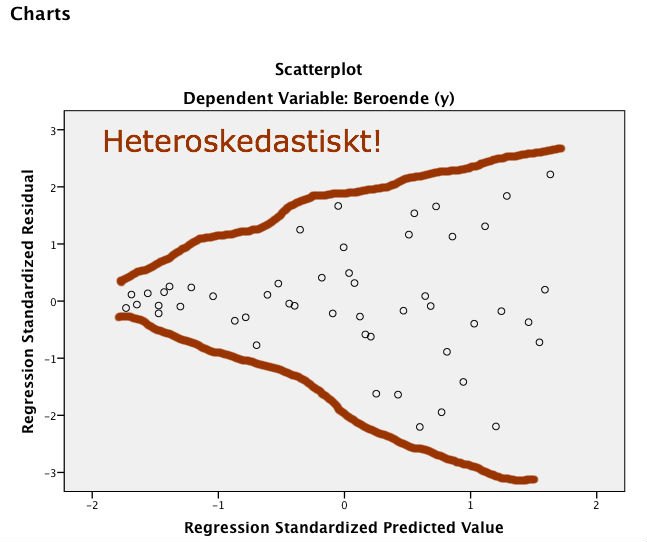
På så vis får vi en scatterplot (figur X) där vi tydligt ser att residualerna är större vid högre förväntade värden på Y (vilket i denna, bivariata, regression alltså är samma som vid högre värden på vår enda oberoende variabel). Vi kan med våra egna ögon se heteroskedasticiteten.
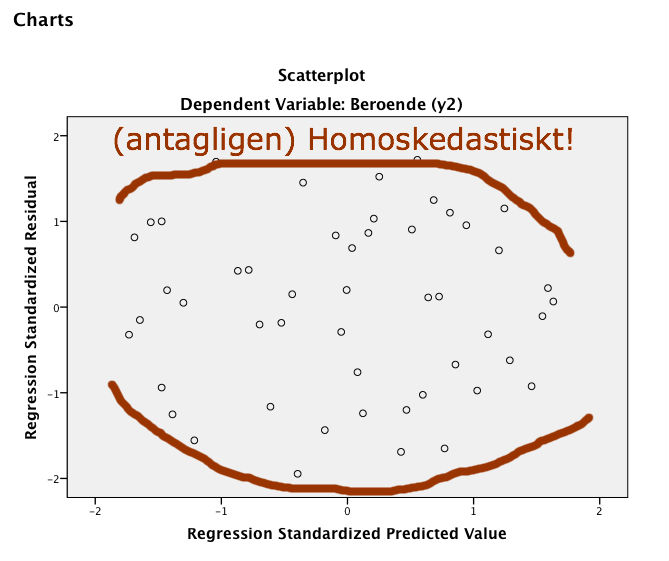
Som en jämförelse visar figur Y upp ett jämt spritt eller ’cigarrformat’, förhållande, där vi alltså inte kan se något problem direkt.
Det finns även mer formella test som genom hypotesprövning prövar om regressionsmodellen är heteroskedastisk. Ett exempel är det så kallade Breusch-Pagan testet som testar hypotesen (H0) om homoskedasticitet. Att göra detta är relativt enkelt, men kräver en del extra steg. Detta avhandlar vi i del två.

Vart är del 2?
Kom gärna med del 2!!! Jag har väntat i månader!!
Nu ligger del 2 uppe! https://spssakuten.wordpress.com/2013/10/28/guide-regressionsdiagnostik-heteroskedasticitet-del-2/
Hej!
Vi har att vår modell liknar ett timglas när vi kollar för heteroskedasticitet. Men när vi gör plottat en och en för de oberoende variablerna så är det de kategoriska variablerna som vi gjort till dummys och bara antar 1 eller 0 som vi får som två bubblor istället för en. Det är dessa som gör att den fulla modellen liknar ett timglas. Kan man då säga att vi har problem?
En annan fråga är om man i PB testet (som du visat i del 2) ska dela på lika många frihetsgrader som man har oberoende variabler. Du delade ju på 1 för att du hade en oberoende variabel.
Tack på förhand
Hej hur lägger man in enkät frågor i SPSS om man har använt pappersform samt har du några tips på olika program som kan användas att samla in kvantitativ data?