
Guide: Stapeldiagram med ”error bars”
I den här guiden ska vi gå igenom:
- Varför det kan vara intressant att göra ett stapeldiagram med error bars
- Hur man gör ett stapeldiagram med error bars
- Hur det förhåller sig till signifikanstestning med ANOVA
När man redovisar resultat från statistiska analyser bör huvudmålsättningen vara att det ska vara så enkelt som möjligt för läsaren att förstå vad man har kommit fram till. Ett bra medel för att göra det lätt för läsaren är att använda olika typer av grafiska diagram. Ett diagram som många förstår och snabbt ger en överblick är stapeldiagram. De lämpar sig till exempel väl för at redovisa medelvärden i olika grupper. I experimentella studier är det vanligt att man redovisar medelvärdena i de olika experimentgrupperna med ett stapeldiagram, och så gör man sedan den riktiga analysen med en ANOVA.
Man kan också lägga till ”error bars”, streck som visar konfidensintervallet kring medelvärdena för att ge läsaren en indikation på om det är troligt att medelvärdena är signifikant åtskilda.
När man gör ett urval ur en population kan man räkna fram ett konfidensintervall kring ett medelvärde. Ett 95-procentskonfidensintervall visar det intervall som det sanna medelvärdet (alltså det som gäller för hela populationen) kommer återfinnas i 95 procent av gångerna om vi gör upprepade slumpmässiga urval. Med hjälp av dessa konfidensintervall kan man sedan pröva om två medelvärden är signifikant åtskilda.
Antag till exempel att man undersöker var män och kvinnor placerar sig på en ideologisk vänster/högerskala. Vi gör ett urval på 1000 personer i Sverige, 500 kvinnor och 500 män. Medelvärdet för kvinnor blir 4,7 och medelvärdet för män blir 4,8. Betyder det att vi kan dra slutsatsen att kvinnor står längre till vänster än män? Nej, för konfidensintervallet är för kvinnor kanske 4,5-4,9 och för män 4,6-5,0. Det betyder att medelvärdet vi fått om vi frågat alla kvinnor i Sverige mycket väl kunde vara 4,8. På samma sätt kan medelvärdet för män mycket väl vara 4,7. Det blir alltid en viss osäkerhet när man bara undersöker ett urval, och inte hela populationen. Därför kan vi inte vara säkra på att kvinnor står längre till vänster.
Om konfidensintervallen istället inte hade överlappat, till exempel om det för kvinnor varit 4,0-4,4 så hade vi med stor säkerhet kunnat säga att kvinnor i Sverige generellt står längre till vänster än män.
Men det kan vara så att konfidensintervallen överlappar, och en signifikansprövning visar att medelvärdena ändå är signifikant åtskilda. Jag har skrivit mer om det i ett annat inlägg.
Hur man gör ett stapeldiagram
Jag använder mig i det här exemplet av QOG-datamängden. Som illustration tänkte jag undersöka om nivån av korruption skiljer sig mellan länder med olika juridisk tradition, ”legal origin,” som det finns en del teorier om. Framförallt handlar teorierna om att engelsk ”common law” som bygger mycket på praxis förväntas ge bättre utfall än fransk lag som bygger på några grunddokument med kärnprinciper.
För att göra diagrammet går man in på menyn ”Graphs->Chart builder.” Där väljer man ”Bar” i menyn längst ner, drar in minitiaryrbilden längst till vänster in i det stora vita fältet, och drar in sin oberoende variabel (som bör vara på nominalskalenivå) till x-axeln och sin beroende variabel (som bör vara på intervallskalenivå) till y-axeln. Förinställningen är att staplarna visar medelvärdet på den beroende variabeln men det går att ändra. Det är oftast det man är intresserad av.
Staplarna som visas direkt (som i Bild 1) är bara exempel, och visar inte de sanna värdena. Ser de inte ut som på bilden, om de till exempel är smala som streck, beror det på att skalnivån på den oberoende variabeln inte är rätt inställd.
Därefter klickar man i ”Display error bars” i rutan till höger, och klickar i ”Confidence intervals”. Förinställningen är att det är ett 95-procentskonfidensintervall, vilket är kutym.
Tryck sedan på OK. Resultatet ska se ut som i Bild 2.
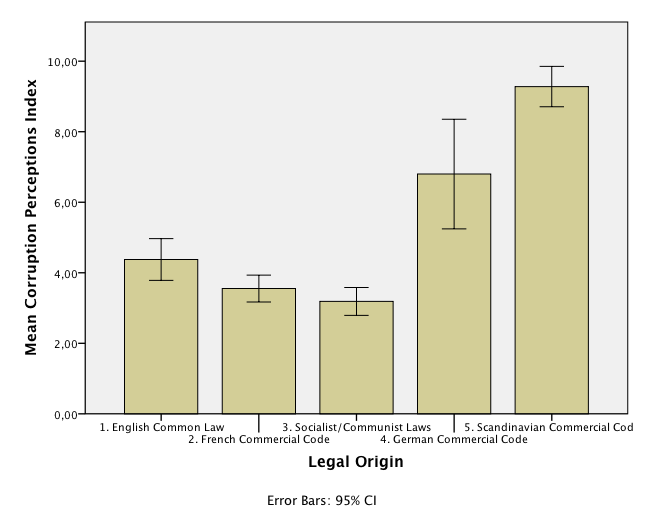
Man ser snabbt att genomsnittet är högst (minst förekomst av korruption) i länder med ”Scandinavian commercial code” och lägst i länder med ”Socialist/Communist Laws”. Det här är stapeldiagrammets styrka – det är enklare att se medelvärdesskillnader än i en tabell. Felstaplarna varierar i omfång. För länder med ”German commercial code” är felstapeln mycket större, vilket beror på att det är ganska få länder med stor spridning som har det här systemet. Konfidensintervallet blir då större än om det varit fler länder.
Konfidensintervallen för ”French commercial code” och ”Socialist communist laws” överlappar en hel del, vilket tyder på att det är osannolikt att de här grupperna skulle vara signifikant åtskilda. Däremot är det troligt att länder med till exempel ”English common law” är signifikant lägre än länder med ”Scandinavian commercial code” eftersom de konfidensintervallen inte överlappar alls.
Hur stapeldiagram med error bars förhåller sig till ANOVA
För att undersöka om så är fallet gör vi en ANOVA, en envägs variansanalys. Resultatet visas i Bild 3.
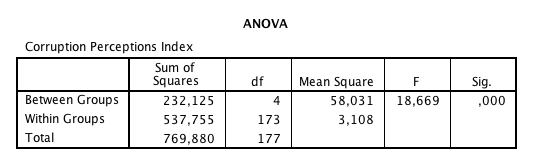
En variansanalys visar om det är troligt att alla medelvärden är samma i den stora populationen, eller om minst två medelvärden kan förväntas skilja sig åt (signifikanstester är som sagt utvecklade för jämförelser i urval – här handlar det ju inte om ett urval av länder, vilket gör att signifikanstester egentligen inte är tillämpbara. Likväl används de ofta på den här typen av data ändå). Signifikansvärdet är ,000 vilket innebär att det är osannolikt att alla medelvärden är desamma – inte så konstigt med tanke på vilka stora skillnader man kunde se mellan länder med ”Scandinavian commercial code” och resten.
För att se vilka medelvärden det är som som skiljer sig åt gör vi ett post hoc-test. Resultatet visas i Bild 4.
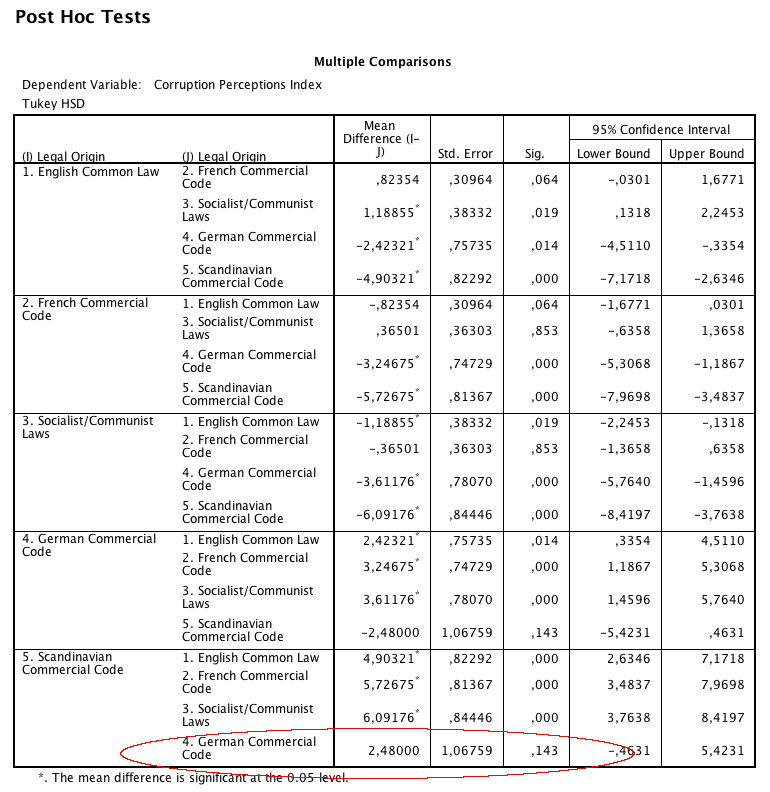
Varje medelvärde jämförs här med de i de fyra andra grupperna. Titta på den nedersta rutan, där ”Scandinavian..” jämförs med övriga. Signifikansvärdena för jämförelserna med ”English”, ”French” och ”Socialist” är alla ,000, vilket betyder att de är signifikant åtskilda. Däremot är signifikansvärdet för jämförelsen med ”German…” ,163, vilket betyder att medelvärdena inte är signifikant åtskilda. Detta trots att konfidensintervallen inte överlappade. Varför?
Det har att göra med att vi när vi har fem medelvärden gör en mängd olika jämförelser: 4+3+2+1=10 faktiskt. Signifikansvärdena i post hoc-testet är anpassat för att det ska vara 95 procents säkerhet att vi inte gör något fel i någon av jämförelserna. Gör man ett test med 05 procents säkerhetsnivå är sannolikheten att man inte gör något fel 95 procent. Om man däremot gör två tester där sannolikheten att man inte gör något fel på varje test blir sannolikheten att man inte gör något fel på de båda testen 0,95*0,95. Gör man tre tester blir det 0,95*0,95*0,95, och så vidare. Gör man tio tester med 95 procents säkerhet är det faktiskt bara 60 procents chans att man inte gör något fel!
Ju fler jämförelser vi gör samtidigt, desto högre behöver säkerhetsnivån vara för att det ska vara 95 procents sannolikhet att vi inte gör något fel. Därför skulle konfidensintervallen behöva vara satta till något mycket högre, vilket skulle göra dem större, för att de skulle motsvara resultaten från ANOVAn.
Därför kan man inte vara helt säker på om två medelvärden är signifikant åtskilda genom att bara titta på ett stapeldiagram med error bars, men de ger en lättöverskådlig indikation, och är därför ett bra komplement till en ANOVA.

Hej!
Jag har en fundering, hur genomför man så kallade in-sample och out-sample analyser?
Hej,
Den här sidan kommer att bli min räddning. Jag blir snart ekonom bara jag får min undersökning klar….! Jag gillar er! :)
Har IBM SPSS 23.
Hur adderar man min/max error bars istället för standard deviation eller confidence interval?
I SPSS finns att välja mellan standardavvikelse eller confidence interval. Ingen möjlighet att välja min/max bars. Hittar inte ens en diskussion om min/max error bars i SPSS på internet.