
I den här guiden ska vi:
- Jämföra om skillnaderna mellan en faktisk fördelning i ett urval och en förväntad fördelning är orsakad av slump eller av något annat
- Genom att räkna ut Chi2-värdet för hand
- Och jämföra det med ett kritiskt värde
- …och i SPSS.
I statistisk analys jämför vi ofta olika grupper med varandra. Men ibland vill vi jämföra en grupp med en teoretisk referenspunkt. Om vi tror att verkligheten ser ut på ett visst sätt, gör ett urval och får ett resultat som skiljer sig något från det vi trodde, beror det då på slump i urvalet, eller hade vi fel idé om verkligheten?
Ett exempel på när detta kan vara relevant är när man letar efter valfusk. Även om man inte vet vad folk ska rösta på så kan man göra några antaganden om hur många som röstar. Den så kallade Benfords lag visar att den första siffran i antalet röster i ett valdistrikt bör fördela sig på ett visst sätt. Det bör vara fler ettor än tvåor, fler tvåor än treor, osv. Samtidigt finns det ett uttrymme för slump. Är avsteget från den förväntade fördelningen inom ramen för slumpvariationen, eller beror den på att någon till exempel manipulerat röstsiffrorna?
Räkna ut Chi2 för hand
Vårt mer triviala exempel handlar om godiset Non Stop. Är det troligt att fabriken tillverkar lika många godisar av varje färg, eller finns det någon systematik? För att ta reda på det räknade jag hur många det var av varje färg i en påse.
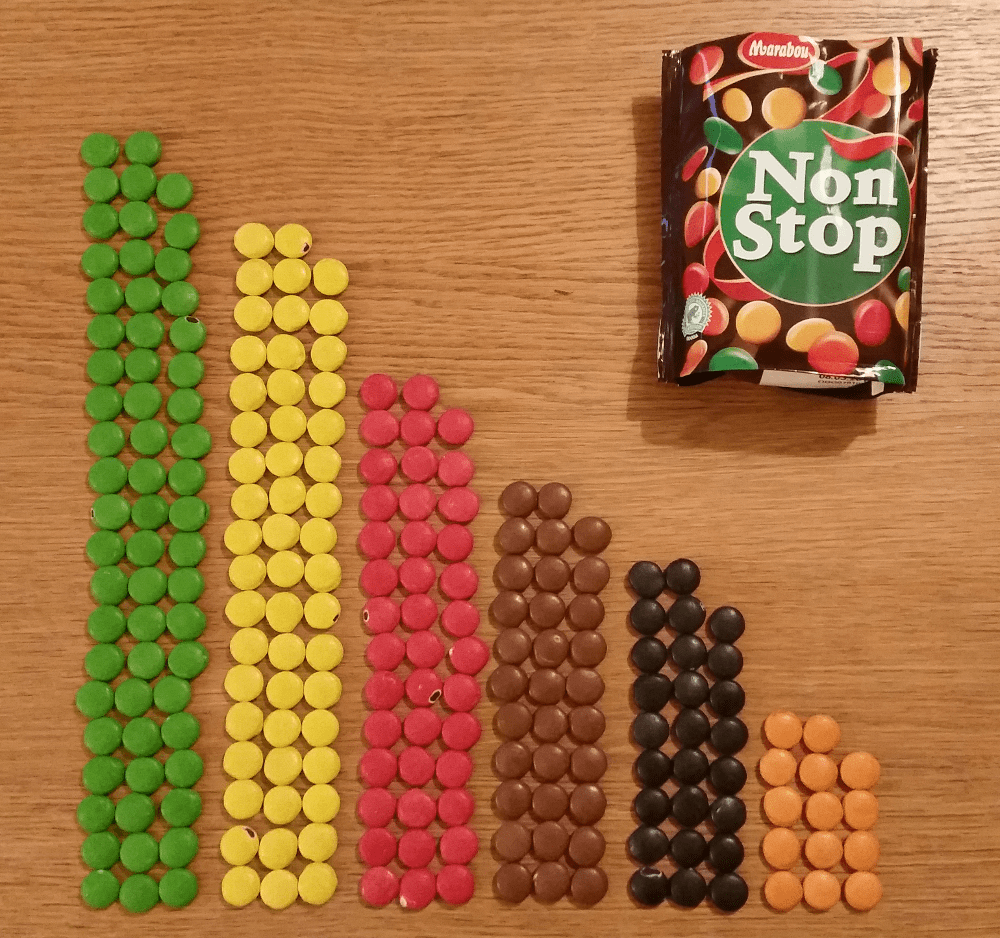
Av de 228 godisbitarna var hela 62 gröna, medan bara 14 var orangea, som man kan se i grafen här. Den förväntade fördelningen, givet hypotesen att de tillverkar lika många av varje färg, är att det borde vara 38 stycken av varje. Vi ska nu räkna fram det så kallade Chi2-värdet. Det kan sedan jämföras mot ett kritiskt värde för att se hur ”normalt” vårt utfall är.
Formeln är som följer:

O står får det Observerade värdet, i det här fallet antalet godisar av en viss färg. E står för det förväntade (Expected) värdet, det vill säga 38. För varje färg tar vi alltså skillnaden mellan det observerade antalet och det förväntade, kvadrerar denna skillnad (alltså multiplicerar den med sig själv), och dividerar sedan det vi får fram med det förväntade värdet. Sigmatecknet (det kantiga E:et) betyder sen att vi ska summera denna uträkning för alla färger. I tabellen nedan har jag gjort just det:
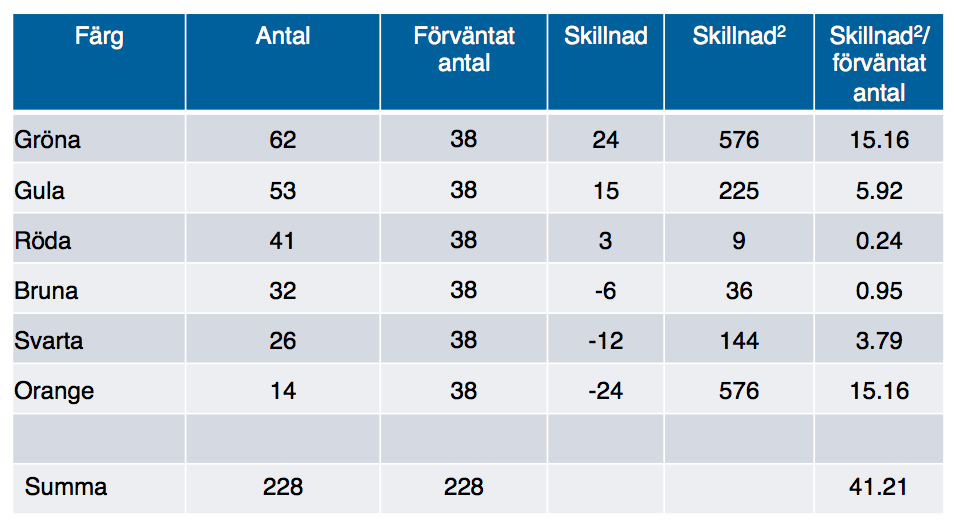
Värdet vi får fram nere till höger, 41.21, är Chi2-värdet.
Jämföra Chi2 med ett kritiskt värde
Men är nu det högt eller lågt? Det är kanske helt normalt om man gör en slumpmässigt urval från en stor bunke med lika många nonstops av varje färg? Vi behöver inte gissa, utan kan rådfråga en tabell med kritiska värden, eller använda en automatisk kalkylator. En sådan finns till exempel här.
Man behöver där först ange df, vilket står för degrees of freedom, frihetsgrader. Utan att gå in på de matematiska definitionerna betyder det i det här fallet hur många kategorier vi jämför, minus ett. Eftersom vi har sex färger blir det 5.
Sedan skriver man i rutan x in sitt Chi2-värde, alltså 41.21. I den sista rutan visas sedan hur stor sannlikhet det är att vi får minst ett så här stort värde, om det bara är slumpen som spelar roll. Sannolikheten är i princip 0. Man kan även skriva in en sannolikhet, till exempel 0.05, och se hur högt Chi2 minst behöver vara för att vi ska vara minst 95% säkra på att det inte var slump. Det blir 11.07. 41.21 är skyhögt över, vilket tyder på att det inte är slump.
Vi kan därför, utifrån det här testet, förkasta nollhypotesen. Troligtvis görs det inte lika många av varje färg – vår fördelning är alltför osannolik för det. Men det kan också finnas andra förklaringar, till exempel att man inte stoppar ner godisbitarna i påsen en och en, utan kanske tar stora sjok, och då blir det inte ett perfekt slumpmässigt urval. Själv skulle jag tro att det är den troligaste förklaringen!
Räkna ut Chi2 i SPSS
Hur gör man då detta i SPSS? Först gör man ett dataset med 228 observationer, och en variabel, ”color” (undvik å, ä och ö i variabelnamn!). 62 observationer får värdet 1 för grön, 52 får värdet 2 för gul, osv.
Därefter klickar man på Analyze->Nonparametric tests->Legacy dialogs->Chi-square. Man klickar i sin variabel, och anger ”All categories equal”. Om man har någon annan teoretiskt förväntad fördelning kan man ange den genom att klicka i ”Values” istället. Därefter är det bara att klicka på ”OK”.
I outputen är rutan ”Test statistics” det intressanta. Vi ser där både ”Chi-square”, antalet frihetsgrader, och signifikansvärdet (”Asymp. Sig”). I vårt fall blir det .000, vilket betyder att det är i princip noll sannolikhet att vi skulle få en sån här skev fördelning givet att populationen som vi drog godisarna ur hade lika många av varje färg.

Pluggar på Uni just nu, och föreläsaren gjorde att fasansfullt jobb med att förklara Chi-Två. Det här har hjälpt otroligt- väldigt pedagogisk, tackar! :)
Kan bara hålla med ovanstående
Fundering: Hur gör jag om det väntade värdet är 0 för en av cellerna? då blir ju divisionen med noll. Finns det något annat test i denna situation för oparade ordinaldata?